Software environment
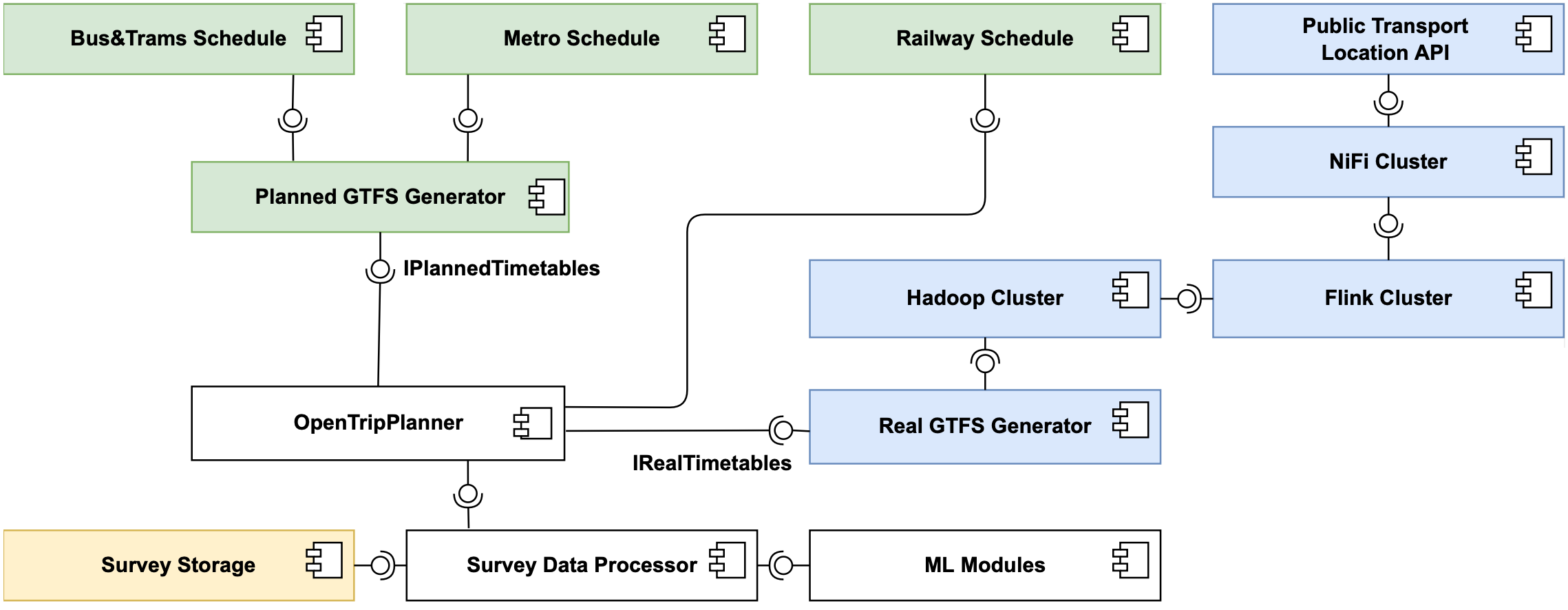
In our works we develop data systems used to collect, transform, ingest and analyse data of different modalities. We work with data streams e.g. sensor readings e.g. weather data from meteo stations, public transport delay data, spatial data e.g. road network layers, tabular data, trip matrices from transport models and more.
To make the processing of varied data possible, we have developed extensible software platforms, combining Relational Database Management Systems and Big Data platforms for data collection, storage, and event streaming. These include Apache NiFi, Apache Hadoop, Apache Flink, and Apache Kafka. An important part of our platforms are custom modules, including batch and stream jobs relying on stream processing engines such as Apache Flink and RESTful services calculating features used for machine learning tasks such as travel mode choice prediction. We use these platforms for inter alia detecting changes in data streams with stream mining methods, modelling delays and predicting travel mode choices.